
Get in Touch
Whether you want to collaborate, discuss product strategy, or explore speaking opportunities — I’d love to connect.
Read Our Latest Blogs
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Preventive maintenance: Replacement vs. Detection
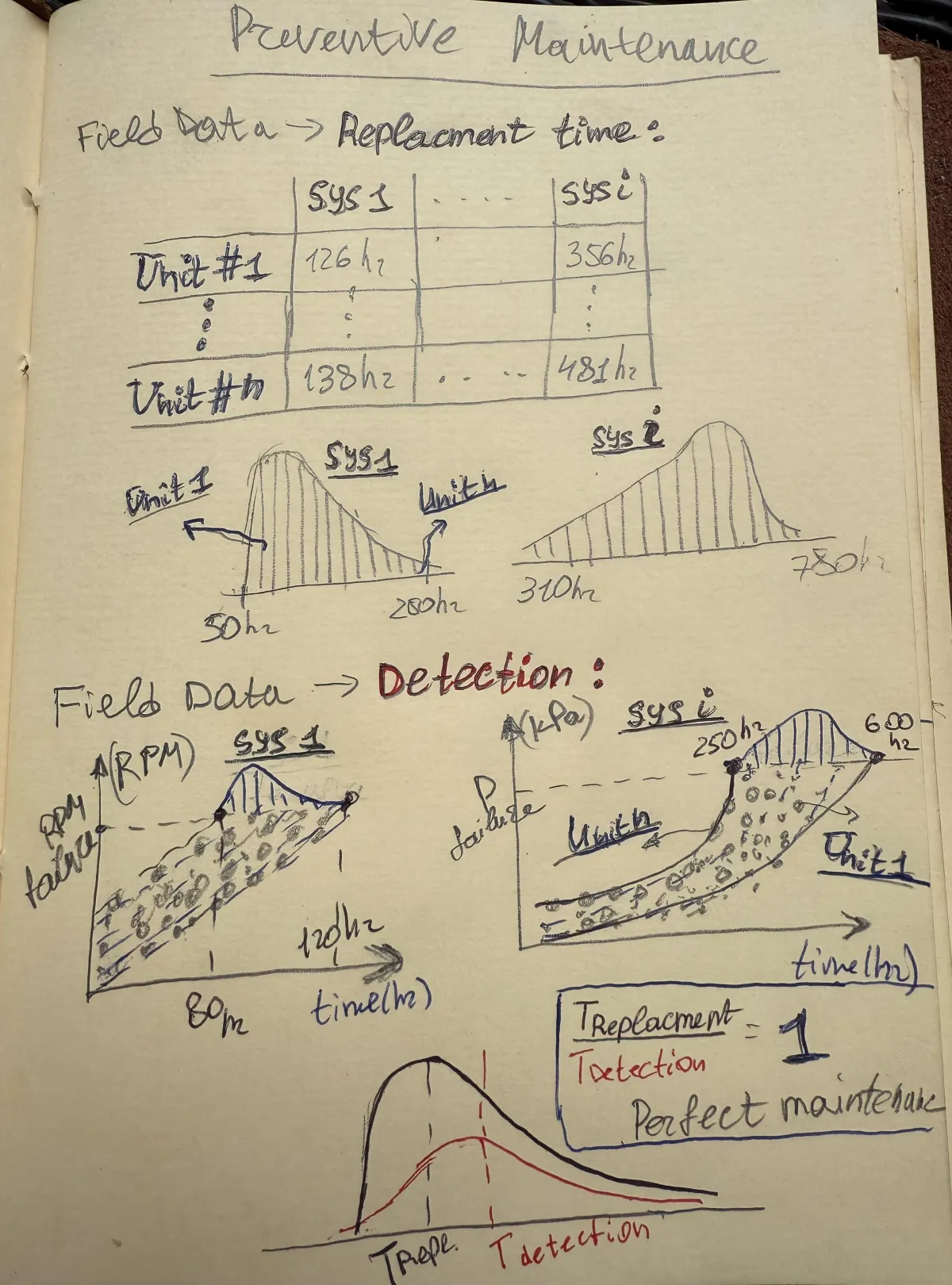
Preventive maintenance boils down to a single question: When should we act before a failure acts on us? Two dominant schools of thought answer differently. A time-based replacement program schedules service after a fixed number of hours, cycles, or calendar days, betting that history is a good proxy for future risk. A condition-based detection program monitors a health indicator—vibration, temperature, pressure drop—and intervenes the moment that signal crosses an alarm limit. Understanding how they contrast is essential for designing a maintenance plan that balances uptime, cost, and risk.
Time-based replacement is the simpler path. You gather run-to-failure data, pick an interval comfortably before the average wear-out age, and standardize it across the fleet. The upside is predictability: parts, labor, and downtime can be budgeted a year in advance, and no sensors or analytics infrastructure are required. The downside is waste and blindness. Healthy assets are retired with useful life still inside, while abnormal early failures remain invisible until they bite because the calendar, not the machine, sets the schedule.
Condition-based detection turns that logic around. Instead of predicting failure statistically, it measures degradation directly. A bearing’s crest factor, a pump’s discharge pressure ripple, or a motor’s winding temperature becomes a real-time window into wear. Interventions happen only when a specific unit signals distress, extracting maximum life from benign assets and catching outliers before they cascade into secondary damage. The trade-offs are upfront investment in sensors and data pipelines, plus the continuous tuning of alarm thresholds as operating conditions evolve.

Many reliability teams blend the two into a hybrid policy. A conservative replacement ceiling acts as a safety net against sensor blind spots, while condition-based triggers drive day-to-day decisions. This layered approach delivers both predictability and responsiveness: if the data stream goes dark, the replacement interval still protects uptime; if the data stream is healthy, detections fine-tune interventions to the actual wear curve.
Implementation success hinges on organizational readiness, not just technology. Planners must align spare-parts logistics with variable detection dates, technicians need training to trust sensor alarms over habit, and finance teams should recognize that higher first-year costs for instrumentation often pay back through reduced catastrophic failures. Equally important, data science and domain expertise must collaborate; a great algorithm without field-savvy validation can trigger as many false positives as a miscalibrated pressure gauge.
Ultimately, the replacement vs detection debate is less an either-or choice than a slider you adjust for business criticality, budget, and risk appetite. Low-cost consumables with no measurable precursor still make sense on a fixed schedule, while high-value assets that telegraph their health deserve the nuance of condition monitoring. The reliability engineer’s craft lies in dialing that slider to where cost, complexity, and confidence converge—pre-empting downtime without overspending on insurance policies disguised as maintenance.


© 2025- All Rights Reserved.